분산 시스템에서 유일한 ID를 생성하는 일은 생각보다 복잡하다.
단순히 RDBMS의 auto_increment를 사용하면 될 것 같지만, 서버가 분산되기 시작하면 곧 병목과 충돌의 문제가 나타난다.
이 글에서는 그러한 문제를 해결하기 위한 다양한 접근법을 소개하고, 그중에서도 트위터의 Snowflake 알고리즘을 중심으로 설계를 정리한다.
데이터베이스 서버 한 대로는 그 요구를 감당할 수 없을뿐더러, 여러 데이터베이스 서버를 쓰는 경우에는 지연시간(delay)을 낮추기가 무척 힘들 것이다.
🤔 여러 데이터베이스 서버를 쓰는 경우에 지연시간을 낮추기가 힘들다는 게 무슨말일까?
ID 충돌을 피하려면 각 DB 서버가 생성하는 ID 범위를 미리 조정하거나, 중앙에서 ID를 발급받는 티켓 서버 같은 구조를 사용해야 한다.
이 경우에도 결국 ID 생성 요청은 특정 서버 또는 중앙 로직을 반드시 거쳐야 한다.
이 구조에서 발생하는 문제는 다음과 같다.
- 네트워크 통신 비용 증가: 모든 노드가 중앙 서버에 ID를 요청해야 하므로 요청/응답 과정에서 지연이 발생한다.
- 동기화 이슈: 서버 간 상태를 맞추기 위해 추가적인 동기화 작업이 필요하고, 이 또한 지연과 복잡성을 증가시킨다.
- 확장성 한계: 장애나 서버 확장 시 동기화 불일치 문제로 인해, 전체 시스템의 안정성과 응답 시간이 영향을 받는다.
따라서 지연시간을 낮추기 위해 각 서버가 독립적으로 ID를 생성할 수 있는 구조가 이상적이지만, auto_increment 방식은 애초에 중앙 집중형 설계이기 때문에 이와 같은 분산 처리에는 적합하지 않다.
이 점에서 auto_increment는 분산 시스템의 요구 사항과 충돌하게 된다는 말인 것 같다..
1단계. 문제 이해 및 설계 범위 확정
시스템 설계 면접 문제를 푸는 첫 단계는 적절한 질문을 통해 요구사항을 이해하고 모호함을 해소하여 설계 방향을 정하는 것이다.
가령, 요구사항을 다음과 같이 정의해볼 수 있다.
- ID는 유일해야 한다.
- ID는 숫자로만 구성되어야 한다.
- ID는 64비트로 표현될 수 있는 값이어야 한다.
- ID는 발급 날짜에 따라 정렬 가능해야 한다.
- 초당 10,000개의 ID를 만들 수 있어야 한다.
2단계. 개략적 설계안 제시 및 동의 구하기
분산 시스템에서 유일성이 보장되는 ID를 만드는 방법은 여러 가지다. 살펴볼 몇 가지 방법들은 다음과 같다.
- 다중 마스터 복제(multi-master replication)
- UUID(Universally Unique Identifier)
- 티켓 서버(ticket server)
- 트위터 스노플레이크(twitter snowflake) 접근법
1. 다중 마스터 복제
다중 마스터 복제는 대략 다음 그림과 같은 구성을 갖는다.
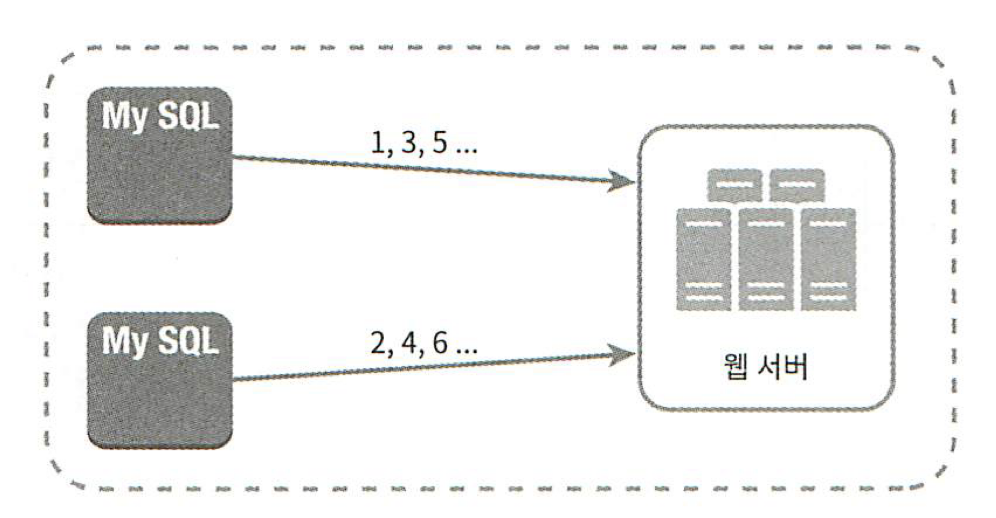
이 접근법은 데이터베이스의 auto_increment 기능을 활용하는 것이다.
다만 ID의 값을 구할 때 1만큼 증가시켜 얻는 것이 아니라, k만큼 증가시킨다.
여기서 k는 현재 사용 중인 데이터베이스 서버의 수다.
위의 그림의 예제를 보자.
어떤 서버가 만들어 낼 다음 아이디는, 해당 서버가 생성한 이전 ID 값에 전체 서버의 수 2를 더한 값이다.
이렇게 하면 규모 확장성 문제를 어느 정도 해결할 수 있는데, 데이터베이스 수를 늘리면 초당 생산 ID 수도 늘릴 수 있기 때문이다.
하지만 이 방법은 다음과 같은 단점이 있다.
- 여러 데이터 센터에 걸쳐 규모를 늘리기 어렵다.
- ID의 유일성은 보장되겠지만 그 값이 시간 흐름에 맞추어 커지도록 보장할 수는 없다.
- 서버를 추가하거나 삭제할 때도 잘 동작하도록 만들기 어렵다.
2.UUID
128비트 크기의 전역적으로 유일한 문자열 ID를 생성한다. Java에서는 UUID.randomUUID()를 사용하여 간단히 생성할 수 있다.
import java.util.UUID;
public class UUIDExample {
public static void main(String[] args) {
UUID id = UUID.randomUUID();
System.out.println(id); // e.g., 09c93e62-50b4-468d-bf8a-c07e1040bfb2
}
}만들게되면 09c93e62-50b4-468d-bf8a-c07e1040bfb2와 같은 형태를 띤다.
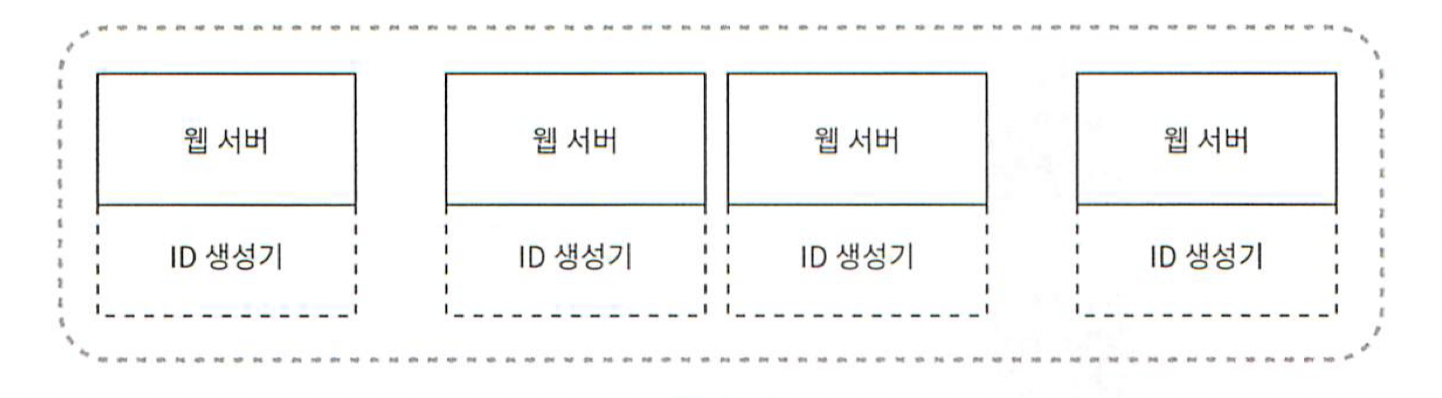
이 구조에서 각 웹 서버는 별도의 ID 생성기를 사용해 독립적으로 ID를 만들어낸다.
장점
- UUID를 만드는 것은 단순하다. 서버 사이의 조율이 필요 없으므로 동기화 이슈도 없다.
- 충돌 가능성이 매우 낮다.
- 각 서버가 자기가 쓸 ID를 알아서 만드는 구조이므로 규모 확장도 쉽다.
단점
- ID가 128비트로 길다. 이전의 ID 요구사항은 64비트이다.
- ID를 시간순으로 정렬할 수 없다.
- ID에 숫자가 아닌 값이 포함될 수 있다.
3. 티켓 서버
중앙 집중식으로 운영되는 ID 발급 전용 서버를 두고, 각 노드는 이 서버에 ID 요청을 보내도록 구성한다.
(플리커가 분산 기본 키를 만들어 내기 위해 이 기술을 이용했다고 한다.)
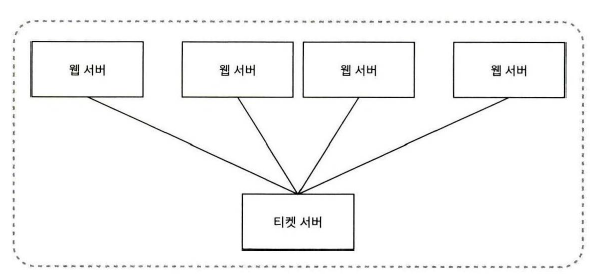
이 아이디어의 핵심은 auto_increment 기능을 갖춘 데이터베이스 서버, 즉 티켓 서버를 중앙 집중형으로 하나만 사용하는 것이다.
장점
- 유일성이 보장되는 숫자로만 구성된 ID를 쉽게 만들 수 있다.
- 구현하기 쉽고, 중소 규모 애플리케이션에 적합하다.
단점
- 티켓 서버가 SPOF(Single-Point-of-Failure)가 된다.
이 서버에 장애가 발생하면, 해당 서버를 이용하는 모든 시스템이 영향을 받는다. 이 이슈를 피하려면 티켓 서버를 여러 대 준비해야 한다. 하지만 그렇게하면 데이터 동기화 같은 새로운 문제가 발생할 것이다.
4. 트위터 Snowflake 알고리즘

Twitter가 설계한 64비트 기반의 고성능 분산 ID 생성 시스템이다.
ID를 비트 단위로 나눠 구성하고, 각 비트에 명확한 의미를 부여해 유일성과 시간순 정렬을 보장한다.
| 항목 | 비트 수 | 설명 |
|---|---|---|
| 사인 비트 (Sign Bit) | 1비트 | 항상 0으로 설정. 현재는 사용되지 않으며 미래 확장을 위해 유보됨 |
| 타임스탬프 (Timestamp) | 41비트 | Epoch(기준 시각, 2010-11-04 01:42:54 UTC) 이후 경과한 밀리초를 나타냄. 시간 순 정렬이 가능해짐 |
| 데이터센터 ID (Data Center ID) | 5비트 | 최대 32개의 데이터센터 구분 가능 (2^5 = 32) |
| 서버 ID (Machine ID) | 5비트 | 각 데이터센터에서 최대 32대의 서버 식별 가능. 총 1024대 (32 * 32) 서버까지 확장 가능 |
| 일련번호 (Sequence Number) | 12비트 | 동일한 밀리초 내에서 생성되는 ID의 구분자. 최대 4096개까지 생성 가능 (2^12 = 4096) |
Snowflake는 총 64비트로 구성되어 있으며, 시간순 정렬 가능하고, 충돌 없이 초당 약 409만 개의 ID를 생성할 수 있다.
3단계. 상세 설계
트위터 Snowflake 알고리즘을 기준으로 설계해보자.
- 데이터센터 ID와 서버 ID는 시스템이 시작할 때 고정적으로 설정된다.
- 이 값들은 운영 중에 바뀌지 않는 것을 전제로 설계되어야 한다.
- 만약 데이터센터 ID나 서버 ID를 실수로 바꾸게 되면, ID 충돌이 발생할 수 있다.
- 따라서 서버 증설이나 설정 변경 시에는 반드시 ID의 중복 여부를 철저히 검증해야 한다.
타임스탬프
- 타임스탬프는 ID 생성기가 작동할 때마다 실시간으로 계산되는 값이며, 스노플레이크 ID에서 가장 큰 비중인 41비트를 차지한다.
- 이 값은 특정 기준 시점(Epoch)부터 현재까지 경과한 밀리초 단위 시간이다.
- 시간이 흐를수록 값이 커지므로, 생성된 ID를 시간순으로 정렬할 수 있는 특징이 있다.
다음의 그림은 앞서 살펴본 ID 구조를 따르는 값의 이진 표현 형태로부터 UTC 시각을 추출하는 예제다.
이 방법을 역으로 적용하면 어떤 UTC 시각도 상술한 타임스탬프 값으로 변환할 수 있다.
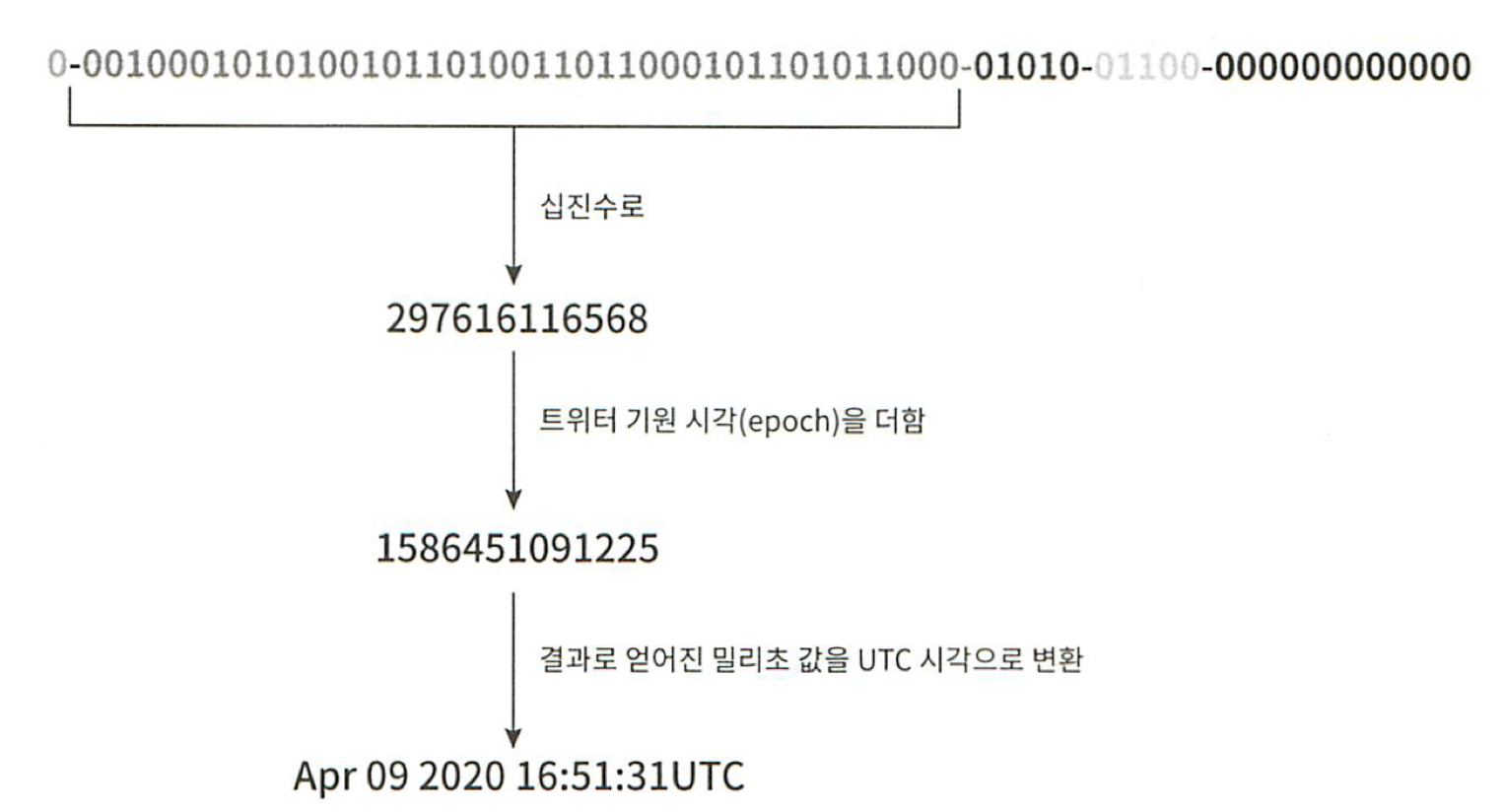
타임스탬프 최대 표현 범위
| 항목 | 값 |
|---|---|
| 비트 수 | 41비트 |
| 최대값 | 241 - 1 = 2,199,023,255,551 (밀리초) |
| 환산 시간 | 약 69년 |
예를 들어, 2,199,023,255,551 밀리초는 약 69년에 해당하며, 이는 다음과 같은 계산으로 도출된다
2199023255551ms ÷ 1000(초) ÷ 60 ÷ 60 ÷ 24 ÷ 365 ≒ 69년
따라서 기원 시각을 현재 기준으로 설정한다면, 앞으로 약 69년간 오버플로 없이 안전하게 ID를 생성할 수 있다.
단, 69년이 지나면 ID 생성이 불가능해지므로, 그 이전에 기원 시각(epoch)을 조정하거나 새로운 ID 체계로 이관해야 한다.
일련번호
- 일련번호는 동일한 밀리초 내에서 생성되는 ID들을 구분하기 위한 값이다.
- 총 12비트가 할당되어 있으며, 표현 가능한 값의 범위는
0 ~ 4095→ 즉 1밀리초 안에 최대 4096개의 ID 생성 가능하다.
일반적인 상황에서는 타임스탬프만으로도 유일성이 확보되지만, 같은 밀리초 내에 다수의 ID를 만들어야 할 경우 이 일련번호가 필요하다.
서버는 밀리초가 바뀔 때마다 이 값을 0으로 초기화하고 다시 증가시킨다.
약 어떤 밀리초 내에서 4096개 이상의 ID를 요청받게 되면, 다음 밀리초까지 대기(wait)하여 새로운 타임스탬프가 나오기를 기다린다.
4단계 마무리
이번 장에서는 유일성이 보장되는 ID 생성기 구현에 쓰일 수 있는 다양한 전략을 알아보았다.
여기서 선택한 방식은 트위터 스노플레이크인데, 모든 요구사항을 만족하면서도 분산 환경에서 규모 확장이 가능했기 때문이다.
추가적으로, 이러한 설계를 진행시 다음과 같은 것들을 추가적으로 생각해봐야 한다.
- 시계 동기화(clock synchronization)
- 이번 스노플레이크 설계에서는 ID 생성 서버들이 전부 같은 시계를 사용한다고 가정하였다. 하지만 이런 가정은 하나의 서버가 여러 코어에서 실행될 경우 유효하지 않을 수 있다. 여러 서버가 물리적으로 독립된 여러 장비에서 실행되는 경우에도 마찬가지다. 이러한 문제점을 해결하는 보편적인 방법으로는 NTP(Network Time Protocol)이 있다.
- 각 section의 길이 최적화
- 예를 들어 동시성(concurrency)이 낮고 수명이 긴 application이라면 일련번호 절의 길이를 줄이고 타임스탬프 절의 길이를 늘리는 것이 효과적일 수도 있을 것이다.
- 고가용성(high availability)
- ID 생성기는 필수 불가결(mission critical) 컴포넌트이므로 아주 높은 가용성을 제공해야 할 것이다.
'💻 Dev > System Design' 카테고리의 다른 글
| 대용량 트래픽을 견디는 콘서트 예약 시스템을 설계해보자 (5) | 2025.08.31 |
|---|---|
| 9장. 웹 크롤러 설계 (0) | 2025.07.14 |
| 8장. URL 단축기 설계 (0) | 2025.07.14 |
| 6장. 키-값 저장소 설계 (0) | 2025.07.01 |
| 5장. 안정 해시 설계 (0) | 2025.06.30 |
| 4장. 처리율 제한 장치의 설계 (0) | 2025.06.30 |