가상 면접 사례로 배우는 대규모 시스템 설계 기초를 읽고 정리한 글입니다.
무상태(stateless) 웹 계층
이제 웹 계층을 수평적으로 확장하는 방법을 고민해 볼 순서다.
먼저 상태 정보(예: 사용자 세션 데이터)를 웹 서버 안에서 제거해야 한다.
왜냐하면 서버마다 상태를 따로 가지고 있으면, 로드밸런서가 클라이언트 요청을 특정 서버로만 보낼 수밖에 없기 때문이다.
바람직한 전략은 이 상태 정보를 관계형 데이터베이스나 NoSQL 같은 지속성 저장소에 보관하고, 필요할 때 가져오는 방식이다.
1. 상태 정보 의존적인 아키텍처
상태 정보를 보관하는 서버는 클라이언트 정보, 즉 상태를 유지하여 요청들 사이에 공유되도록 한다.
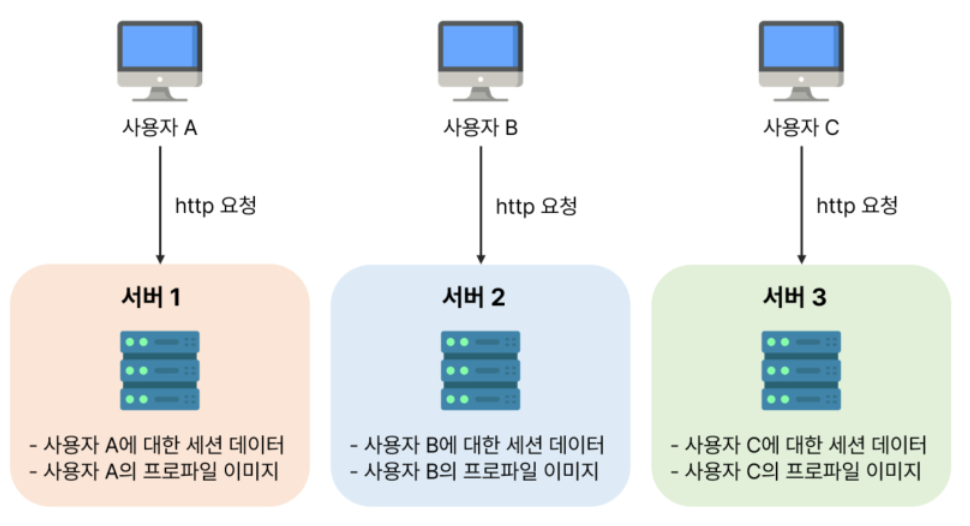
사용자 A의 세션 정보나 프로파일 이미지 같은 상태 정보는 서버 1에 저장된다.사용자 A를 인증하기 위해서 HTTP 요청은 반드시 서버 1로 전송되어야 한다.서버 2에 사용자 A에 관한 데이터는 보관되어 있지 않기 때문에 요청이 서버 2로 전송되면 인증은 실패한다.
같은 클라이언트로부터의 요청은 항상 같은 서버로 전송되어야 한다는 문제가 발생한다.
이 문제 때문에 대부분의 로드밸런서는 고정 세션(sticky session)이라는 기능을 제공한다. 클라이언트가 항상 같은 서버로 요청을 보내도록 고정시키는 것이다.
하지만 이 방식은 몇 가지 단점이 있다.
- 로드밸런서가 세션을 관리하느라 부담이 커진다.
- 서버 추가나 제거, 장애 처리 같은 동적 확장이 복잡해진다.
- 특정 서버에 장애가 나면 해당 사용자는 계속 인증 실패를 겪게 된다.
따라서 큰 규모의 서비스에서는 이 문제를 반드시 해결해야 한다.
2. 무상태 아키텍처
무상태 아키텍처에서는 웹 서버가 상태 정보를 보관하지 않는다.
대신 세션 데이터 같은 상태 정보는 별도의 공유 저장소(shared storage)에 두고, 필요할 때마다 꺼내온다.

위 무상태 아키텍처 구조에서 사용자로부터의 HTTP 요청은 어떤 웹 서버로도 전달될 수 있다.
웹 서버는 상태 정보가 필요할 경우 공유 저장소(shared storage)로부터 데이터를 가져온다.
즉, 상태 정보는 웹 서버로부터 물리적으로 분리되어 있다.
그렇다면! 무상태 아키텍처는 단순하고, 안정적이며, 규모 확장이 쉽다는 말이다.
무상태 웹 계층을 갖도록 변경한 설계

위는 세션 데이터를 웹 계층에서 분리하고 지속성 데이터 보관소에 저장하도록 만들어진 설계다.
공유 저장소로는 관계형 데이터베이스, NoSQL, Redis, Memcached 등 다양한 선택지가 있지만, NoSQL이 많이 쓰이는 이유는 규모 확장이 쉽기 때문이다.
①의 자동 규모 확장(autoscaling)은 트래픽 양에 따라 웹 서버를 자동으로 추가하거나 삭제하는 기능을 뜻한다.
상태 정보가 웹 서버들로부터 제거되었으므로, 트래픽 양에 따라 웹 서버를 넣거나 빼기만 하면 자동으로 규모를 확장할 수 있게 되었다.
데이터 센터
서비스가 전 세계적으로 확장되면, 한 지역의 서버만으로는 성능과 가용성을 보장할 수 없다.
예를 들어 한국에만 서버가 있으면 미국 사용자들은 접속 속도가 느려질 것이다.
따라서 여러 데이터 센터를 운영하는 다중 데이터센터 아키텍처를 구축해야 한다.
2개 이상의 데이터 센터를 이용한 사례
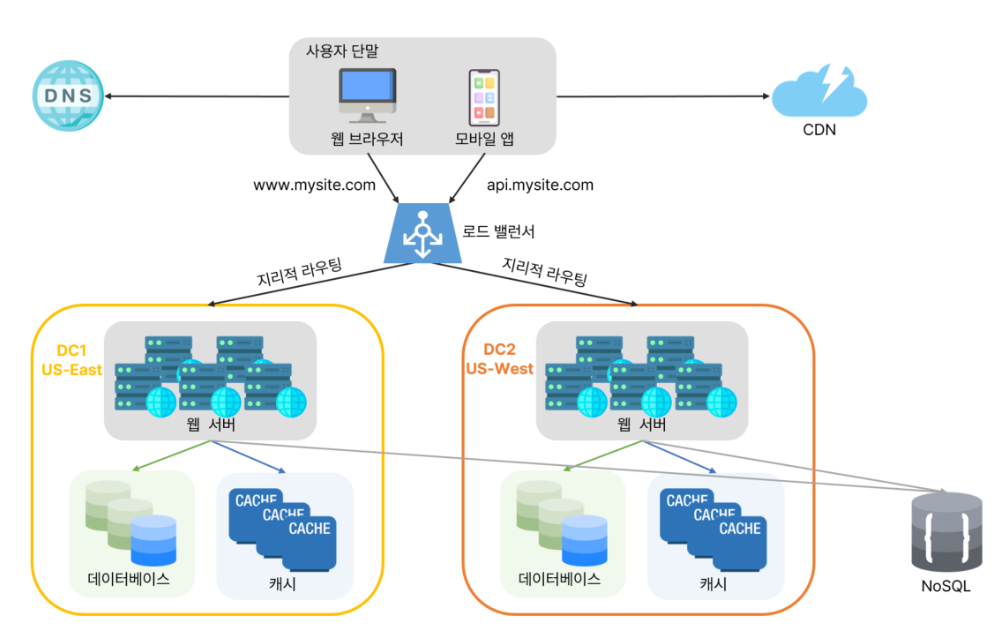
장애가 없는 상황에서 사용자는 가장 가까운 데이터 센터로 안내되는데, 보통 이 절차를 지리적 라우팅(geoDNS-routing 또는 geo-routing)이라고 부른다.
지리적 라우팅에서의 geoDNS는 사용자의 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정할 수 있도록 해 주는 DNS 서비스다.
x% 사용자는 US-East 센터로, 그리고 (100 - x)%의 사용자는 US-West 센터로 안내된다.
사용자들이 웹사이트에 접속할 때, 전체 접속자의 일정 비율(x%)을 미국 동부 데이터센터로 보내고, 나머지 (100 - x)%를 미국 서부 데이터센터로 보낸다는 뜻이다.
하나의 데이터 센터에 장애가 발생하면?
만약 US-West 센터에 심각한 장애가 발생하면, geoDNS는 모든 트래픽을 US-East로 우회시킨다.
이렇게 자동 복구(failover) 덕분에 서비스 전체가 멈추는 것을 피할 수 있다.

이 사례와 같은 다중 데이터센터 아키텍처를 만들려면 몇 가지 기술적 난제를 해결해야 한다.
1. 트래픽 우회
- 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법을 찾아야 한다.
GeoDNS는 사용자에게서 가장 가까운 데이터센터로 트래픽을 보낼 수 있도록 해 준다.
2. 데이터 동기화(synchronization)
- 데이터 센터마다 별도의 데이터베이스를 사용하고 있는 상황이라면, 장애가 자동으로 복구되어(failover) 트래픽이 다른 데이터베이스로 우회된다 해도, 해당 데이터센터에는 찾는 데이터가 없을 수 있다.
- 이런 상황을 막는 보편적 전략은 데이터를 여러 데이터센터에 걸쳐 다중화하는 것이다.
3. 테스트와 배포(deployment)
- 여러 데이터 센터를 사용하도록 시스템이 구성된 상황이라면 웹 사이트 또는 애플리케이션을 여러 위치에서 테스트해 보는 것이 중요하다.
- 자동화된 배포 도구는 모든 데이터 센터에 동일한 서비스가 설치되도록 하는 데 중요한 역할을 한다.
메시지 큐
시스템을 더 큰 규모로 확장하기 위해서는 시스템의 컴포넌트를 분리하여, 각기 독립적으로 확장될 수 있도록 해야 한다.
메시지 큐(message queue)는 많은 실제 분산 시스템이 이 문제를 풀기 위해 채용하고 있는 핵심적 전략 가운데 하나다.
메시지 큐는 메시지의 무손실(durability, 즉 메시지 큐에 일단 보관된 메시지는 소비자가 꺼낼 때까지 안전히 보관된다는 특성)을 보장하는, 비동기 통신을 지원하는 컴포넌트이다. 메시지의 버퍼 역할을 하며, 비동기적으로 전송한다.
메시지 큐의 구조(생산자-소비자)

생산자(or 발행자)라고 불리는 입력 서비스가 메시지를 만들어 메시지 큐에 발행한다.- 큐에는 보통
소비자(or 구독자)라고 불리는 서비스 혹은 서버가 연결되어 있는데, 메시지를 받아 그에 맞는 동작을 수행한다.
메시지 큐를 이용하면 뭐가 좋은데?
메시지 큐를 이용하면 서비스 또는 서버 간 결합이 느슨해져서, 규모 확장성이 보장되어야 하는 안정적 애플리케이션을 구성하기 좋다.
생산자는 소비자 프로세스가 다운되어 있어도 메시지를 발행할 수 있고, 소비자는 생산자 서비스가 가용한 상태가 아니더라도 메시지를 수신할 수 있다.
사진 보정 작업 사례
이미지의 크로핑(cropping), 샤프닝(sharpening), 블러링(blurring) 등을 지원하는 사진 보정 애플리케이션을 만든다고 해 보자.
이러한 보정은 시간이 오래 걸릴 수 있는 프로세스이므로 비동기적으로 처리하면 편리하다.
🤔 왜 오래 걸릴 수 있는 프로세스인가?
사진 보정은 단순히 “데이터를 저장하거나 불러오기” 같은 I/O 작업만이 아니라 CPU, 메모리 자원을 많이 소모하는 작업이다.그 이유는 다음과 같이 추측해 볼 수 있다.
- 고해상도 이미지 처리
- 무거운 필터와 알고리즘(샤프닝이나 블러링 같은 기술은 각 픽셀 주변의 여러 픽셀 값을 함께 고려해야 하므로 훨씬 연산량이 많다.)
이런 작업을 웹 서버에서 동기적으로 처리하면, 한 요청 때문에 다른 요청들이 대기하게 되고, 서버 자원이 특정 작업에 몰려 전체 성능이 떨어진다.
따라서,
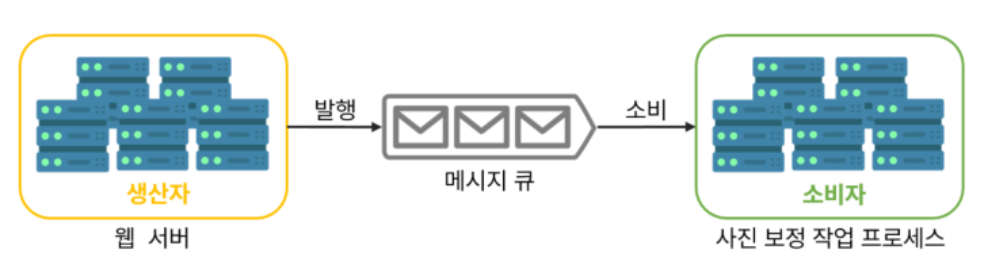
- 웹 서버는
사진 보정 작업(job)을 메시지 큐에 넣는다. - 별도의
사진 보정 작업(worker) 프로세스들은 이 작업을 메시지 큐에서 꺼내어 비동기적으로 처리한다.
이렇게 하면 생산자와 소비자 서비스의 규모는 각기 독립적으로 확장될 수 있다.
이렇게 하면 작업량이 많을 땐 worker를 더 추가해서 처리량을 늘릴 수 있고, 작업량이 적으면 worker 수를 줄여 자원을 절약할 수 있다.
로그, 메트릭, 자동화
시스템이 커지면 문제를 감지하고, 성능을 측정하고, 반복적인 작업을 자동화하는 도구들이 반드시 필요하다.
로그
에러 로그를 통해 시스템 오류를 실시간으로 모니터링할 수 있어야 한다.
각 서버에 흩어져 있는 로그를 한곳으로 모아주는 로그 수집 도구를 쓰면 훨씬 편리하게 검색하고 분석할 수 있다.
메트릭
메트릭을 잘 수집하면 사업 현황에 관한 유용한 정보를 얻을 수도 있고, 시스템의 현재 상태를 손쉽게 파악할 수도 있다.
ex) 호스트 단위 메트릭, 종합 메트릭, 핵심 비즈니스 메트릭
CPU 사용률, 메모리 점유율, API 응답 시간, 일간 활성 사용자 수 등
자동화
시스템이 복잡해질수록 사람 손으로 일일이 배포하거나 관리하기 어렵다.
따라서 CI/CD 같은 자동화 도구를 도입해 배포·테스트·운영을 자동화해야 한다.
위 도구들을 반영하여 수정한 설계는 다음과 같다.

데이터베이스의 규모 확장
저장할 데이터가 많아지면 데이터베이스에 대한 부하도 증가한다. 그땐 데이터베이스를 증설할 수 있다.
데이터베이스 규모를 확장하는 방법엔 수직적 규모 확장법과 수평적 규모 확장법 두 가지로 나뉜다.

수직적 확장
기존 서버에 더 많은, 또는 고성능의 자원(CPU, RAM, 디스크 등)을 증설하는 방법이다.
스택오버플로우는 2013년 한 해 동안 방문한 천만 명의 사용자 전부를 단 한 대의 마스터 데이터베이스로 처리하였다.
하지만 이 방법에는 심각한 약점이 몇 가지 있다.
- 서버 하드웨어를 무한 증설할 수 없으므로 한계가 존재하기 때문에, 한 대로는 결국 감당하기 어려워진다.
- SPOF(Single Point of Failure)로 인한 위험성이 크다.
- 고성능 서버로 갈수록 가격이 올라가므로 비용이 많이 든다.
수평적 확장
데이터베이스의 수평적 확장은 샤딩(sharding)이라고도 부르는데, 더 많은 서버를 추가해 성능을 향상하는 방법이다.
샤딩은 대규모 데이터베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술을 일컫는다.
모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.
즉, 데이터를 나눠서 저장한다.
해시 샤딩 예시
샤드가 4개인 경우 user_id % 4 를 해시 함수로 사용하여 데이터가 보관될 샤드를 결정할 수 있다.
결과가 0이면 0번 샤드, 1이면 1번 샤드에 보관하는 방식이다.

샤딩 전략에서 가장 중요하게 고려할 것
바로 샤딩 키(sharding key, partition key)를 어떻게 정하느냐이다.
샤딩 키는 데이터가 어떤 샤드에 저장되는지 결정하는 하나 이상의 컬럼으로 구성된다.
위 사례의 경우 user_id 가 샤딩 키이다. 샤딩 키를 정할 때는 데이터가 고르게 분할될 수 있도록 하는 게 가장 중요하다.
샤딩은 데이터베이스 규모 확장을 위한 훌륭한 기술이지만 완벽하진 않다.
샤딩을 도입하면 시스템이 복잡해지고 풀어야 할 새로운 문제도 생긴다.
데이터의 재 샤딩(resharding)
(1) 데이터가 너무 많아져 하나의 샤드로는 감당이 어렵거나
(2) 균등하게 데이터 분포가 되지 않아 특정 샤드에 데이터가 몰려 할당된 공간 소모가 다른 샤드에 비해 빠르게 진행될 때 재 샤딩을 고려해야 한다.
이를 샤드 소진(shard exhaustion)이라고도 부르는데, 이런 현상을 해결하기 위해 샤드 키를 계산하는 함수를 변경하고 데이터를 재 배치해야 한다.
유명인사(celebrity) 문제
핫스팟 키(hotspot key) 문제라고도 부른다. 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제다.
페이스북 같은 서비스에서 유명 인사 유저가 모두 한 샤드에 집중적으로 저장되어 있다면, 해당 샤드만 read 연산 때문에 과부하가 걸리게 될 것이다. 이를 위해 유명인사 각각에 샤드 하나씩을 할당해야 할 수도 있고, 더 잘게 샤드를 쪼개야 할 수도 있다.
조인과 비정규화(join and de-normalization)
하나의 데이터베이스를 여러 샤드 서버로 쪼개면 나면, 여러 샤드에 걸친 데이터를 조인하기 힘들다.
이를 해결하는 방법 중 하나는 데이터베이스를 비정규화 하여 조인 없이 하나의 테이블에서 질의가 수행될 수 있도록 하는 것이다.
샤딩을 고려한 아키텍처
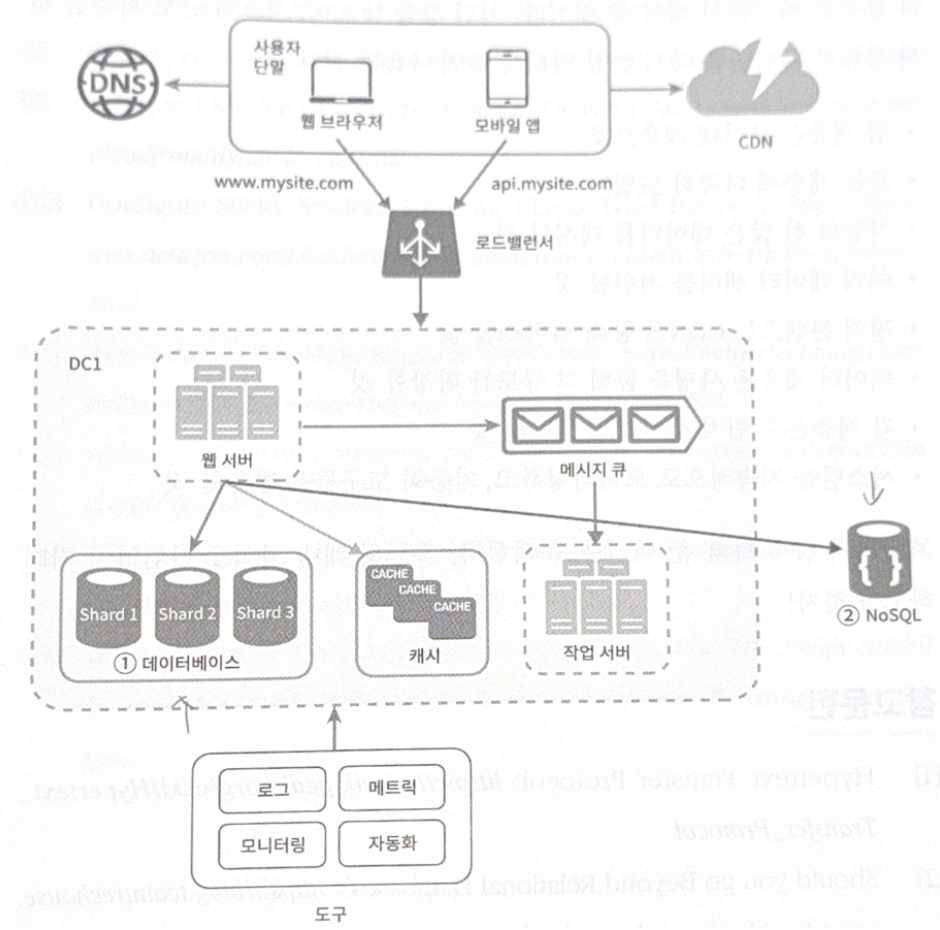
위 구조에서 데이터베이스에 대한 부하를 줄이기 위해 굳이 관계형 데이터베이스가 요구되지 않는 기능들은 NoSQL로 이전하였다.
정리
이번 장에서 다룬 모든 기술은 새롭게 등장하는 도전적 과제를 해결하기 위해 필요한 자양분이 될 것이다.
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 많은 데이터를 캐싱할 것
- 여러 데이터 센터를 지원할 것
- 정적 콘텐츠는 CDN을 통해 서비스할 것
- 데이터 계층은 샤딩을 통해 규모를 확장할 것
- 각 계층은 독립적 서비스로 분리해 관리할 것
- 시스템을 지속적으로 모니터링하고, 자동화 도구들을 활용할 것
1장에서부터 정말 중요한 내용들을 많이 배웠다.
실무에서 운영했던 프로젝트가 비슷한 아키텍처였기 때문에 좀 더 이해하기 쉬웠던 것 같다.
다중 WAS, 분산 DB, 레플리케이션, 로드밸런서, CDN 등..
그때는 상사분들에게 질문하는걸 눈치봤던 시절이기 때문에 웹서버 설정 파일들을 까보면서 WAS 여러대를 이렇게 물리는구나 이 정도만 알고있었다. 이런 아키텍처로 설계하는구나~는 알고 있었지만 왜? 이렇게 확장하고 설계하는지 알 수 있었다.
'💻 Dev > System Design' 카테고리의 다른 글
| 5장. 안정 해시 설계 (0) | 2025.06.30 |
|---|---|
| 4장. 처리율 제한 장치의 설계 (0) | 2025.06.30 |
| 3장. 시스템 설계 면접 공략법 (0) | 2025.06.05 |
| 2장. 개략적인 규모 추정 (0) | 2025.06.04 |
| 1장. 사용자 수에 따른 규모 확장성 - (2) 캐시, CDN (0) | 2025.06.01 |
| 1장. 사용자 수에 따른 규모 확장성 - (1) 규모 확장성의 기초 (0) | 2025.06.01 |