커넥션 풀이란?
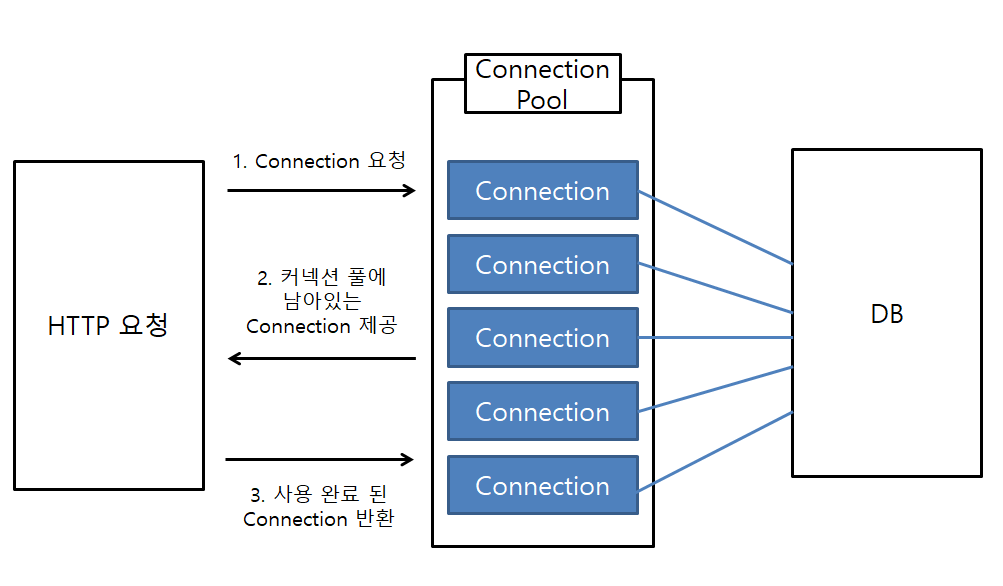
커넥션 풀은 데이터베이스 연결을 미리 생성하여 저장하고, 클라이언트 요청 시 이를 재사용하는 방식이다.
웹 애플리케이션 서버(WAS)가 실행되면 데이터베이스와의 연결 객체를 생성해 풀(pool)에 저장하고, 클라이언트 요청이 오면 이를 빌려주며 작업이 끝나면 반납받아 다시 저장한다.
커넥션 풀이 왜 필요할까?
커넥션 생성에는 높은 비용이 발생한다고 한다.
아래는 한 행을 insert 하는 데 드는 시간을 나타낸다.(괄호 안의 숫자는 비율을 나타낸다)
// MySQL 8.0 Documentation
// https://dev.mysql.com/doc/refman/8.0/en/insert-optimization.html
Connecting: (3)
Sending query to server: (2)
Parsing query: (2)
Inserting row: (1 × size of row)
Inserting indexes: (1 × number of indexes)
Closing: (1)서버가 DB 접속하기 위해서 Connection을 생성하는 작업, 즉 연결 단계가 가장 큰 비용을 차지한다.
왜 연결 단계가 제일 오래 걸릴까?
이유는 데이터베이스와 연결할 때 TCP 통신을 하기 때문이다.
TCP 관련 공부할 때 속도가 느리다는 말을 본 적이 있을 것이다.
TCP 통신은 커넥션의 안정성과 신뢰성 보장을 위해 연결 시 3-way-handshake, 연결 종료 시 4-way-handshake 과정을 거친다.


즉, 데이터베이스와 통신할 때 연결을 맺고 끊는 프로세스들이 추가로 생기기 때문에 시간이 오래 걸리는 것이다.
적절한 커넥션 풀 사이즈
커넥션 풀이 크면 무조건 성능이 좋을까?
질문에 대한 답변은 No다.
우선 WAS에서 커넥션을 사용하는 주체는 스레드라는 걸 인지하고 알아보자.
커넥션 풀이 스레드 풀보다 크면?
이론상으로는 하나의 코어를 가진 CPU가 수백 개의 요청을 ‘동시에’ 처리할 수 있다. 하지만 이는 time-slicing(시분할) 기법 때문에 동시에 동작하는 것으로 보이는 것이지, 실제로는 하나의 코어는 동시에 하나의 작업만 처리할 수 있다.
즉, 빠르게 여러 개의 작업을 컨텍스트 스위칭하며 동작하기 때문에 ‘동시에’ 동작하는 것처럼 보이는 것뿐이다.
따라서 단순히 커넥션 풀 사이즈를 키운다고 해서 무조건적으로 처리가 빨라지는 것은 아니다!
예를 들어 커넥션 풀 사이즈가 10인데 스레드가 5개면?
스레드 열심히 굴려도 커넥션 5개밖에 못 쓰는거다.
즉, 남는 유휴 커넥션들이 메모리 공간을 잡아먹어 리소스 낭비가 발생한다.
따라서 스레드 풀 크기 >= 커넥션 풀 크기가 되어야 한다.
그럼 하나의 코어에 하나의 커넥션만 생성하면 될까?
이상적으로는 하나의 CPU 코어에 하나의 커넥션만 생성하는 것이 효율적일 수 있다.
컨텍스트 스위칭을 하지 않아도 되니까
하지만 실제로는 디스크와 네트워크가 변수로 작용한다. 디스크 I/O 또는 네트워크 작업을 하는 동안은 스레드가 블로킹되어 다른 작업을 할 수 없기 때문이다.
따라서 블로킹되어있는 동안 다른 작업을 처리하면 성능이 좋아지지 않을까?
그러니 `커넥션 풀 사이즈 > CPU 코어 개수`가 좋다.
커넥션 풀이 너무 적으면?
커넥션 풀의 동작 방식을 보면 스레드는 다른 스레드가 커넥션을 반환할 때까지 대기한다.
그래서 커넥션 풀을 너무 작게 설정하면 커넥션을 획득하기 위해 대기하는 스레드가 많아져, 스레드가 불필요하게 낭비되고, 컨텍스트 스위칭이 증가해 성능이 저하된다.
커넥션 풀 크기 계산 공식
그래서 어쩌라는 거냐!
HikariCP(스프링 부트의 디폴트 커넥션 풀)와 PostgreSQL이 권장하는 공식이 있다.
CPU 코어와 데이터베이스의 동시 처리 능력을 고려해 커넥션 풀 크기를 설정하라고 권장한다.
connections = (core_count * 2) + effective_spindle_count
core_count * 2
CPU 코어 수에 2를 곱한 값이다.
2를 곱하는 이유는 Context Switching 및 Disk I/O와 관련이 있다.
Context Switching으로 인한 오버헤드를 고려하더라도 데이터베이스에서 Disk I/O(혹은 DRAM이 처리하는 속도)보다 CPU 속도가 월등히 빠르다.
그러므로, 스레드가 디스크 I/O 또는 네트워크 작업으로 블로킹되는 시간에 다른 스레드의 작업을 처리할 수 있기 때문이다.
effective_spindle_count
effective_spindle_count은 하드 디스크와 관련이 있다.
하드 디스크 하나는 spindle 하나를 갖는다.
요청을 처리할 때 이 spindle을 회전시켜 처리한다.
ex) 디스크가 16개 있는 경우, 시스템은 동시에 16개의 I/O 요청을 처리할 수 있다.
즉, effective_spindle_count은 기본적으로 DB 서버가 관리할 수 있는 동시 I/O 요청 수이다.
공식 적용 예시
- CPU 코어: 4개
- 디스크: 8개
connections = (4 * 2) + 8 = 16이 경우 적절한 커넥션 풀 크기는 16이다.
하지만 공식을 참고하되 각자 애플리케이션에 맞게 시뮬레이션한 후 튜닝하는 것이 가장 적절하지 않을까 싶다.
HikariCP 공식 위키 문서: About Pool Sizing
HikariCP 공식 위키 문서에 커넥션 풀 사이즈에 대한 얘기가 있어 가볍게 보면 좋을 것 같다.
커넥션 풀 사이즈를 줄이는 것이 오히려 성능에 좋다는 내용이다.
번역 1: 커넥션 풀 사이즈에 대하여
번역 2: Connection Pool Size를 줄이면 오히려 성능이 개선될 수 있다.
참고
About Pool Sizing
커넥션과 커넥션 풀(Feat. ThreadPool, HikariCP)
Connection pool
Connection Pool과 적절한 Size 설정하기 (with HikariCP)
'👶🏻 CS > Operating System' 카테고리의 다른 글
| 교착상태와 해결법 (0) | 2024.11.15 |
|---|---|
| 캐시 (0) | 2024.11.12 |
| Concurrent(동시성) vs Parallel(병렬성) (0) | 2024.11.09 |
| 가상메모리와 페이지 교체 알고리즘 (0) | 2024.11.08 |
| 프로세스와 스레드 (0) | 2024.11.07 |
| 임계 구역(Critical Section)과 뮤텍스, 세마포어, 모니터 (0) | 2024.11.01 |